Chapter#17 Swapping
- Swapping
- Replacement Policy
Swapping
Swap Space
page 이동을 위해 disk에 저장하는것
OS는 page-sized unit만큼의 swap space를 기억해 둬야함
Page Table with Swapping
PTE는 additional bit를 가져 present(or valid)한지 확인한다
- 1 : 페이지는 physical memory에 존재한다
- 0 : 페이지는 physical memory에 존재하지 않지만, disk에 존재한다
Page Hit : Virtual Memory(disk)에 존재하며 physical memory에 올라온 word를 참조 (DRAM cache hit)
Page Fault : Virtual Memory(disk)에 존재하며 physical memory에 올라오지 않은 word 참조 (DRAM cache miss)
- page miss가 page fault를 일으킨다
- OS page-fault handler가 victim page를 선택한다 (to replace page)
- victim page 자리에 disk에서 new page를 불러와 대체한다

Page Replacement
page-replacement policy : victim선택 및 replce하는 process의 정의
- swapping은 매우 비싼 작업이므로 policy가 중요하다 ( Disk는 DRAM의 1만배 느림 )
- H/W에서 관리하기에는 매우 복잡하고 open-ended하다
EAT(Effective Access Time)
= (1-p) x memory access + p x (page-fault time)
= (1-p) x 200 + p x 8,000,000
= 200 + 799800 x p (ns)
( 0<=p<=1 page fault 확률, memory access = 200ns, page-fault time = 8mx(8,000,000ns) )
working set : active virtual pages -> the better temporal locality, the smaller working sets
if working set size < main memory size : 좋은 퍼포먼스를 보임
if working set size > main memory size : Thrashing(page가 swapped되면서 퍼포먼스 하락)
Replacement 발생 시기
Laze Approach : OS는 메모리가 다 찰 때까지 기다렸다가, 그제서야 page를 replce함
Swap Daemon, Page Daemon ( Background Thread, *daemon : 백그라운드에서 도는 프로그램 )
- OS가 사용할 수 있는 page 수가 Low Watermark(LW)보다 작아지면, 해당 스레드가 돌며 사용가능한 page 수가 Hight Watermark(HW)와 같아질 때 까지 page를 정리한다
Replacement Policy
Goal : minimize EAT = minimize the number of cache miss
Optimal Replacement Policy
가장 멀리 accessed될 page를 replace해야됨
cache msis가 가능한 안나도록 해야됨
Simple Policy : FIFO
queue를 사용하여 page replacement처리
Belady's Anomaly
일반적으로 cache크기가 커지면 hit rate가 증가함 그러나 FIFO는 가끔 page frame이 커져도 더 낮은 hit ratio를 보임

Simple Policy : Random
말그대로 random한 page를 victim으로 선택. 생각보다 잘 되기도 한다
Histroy 사용
Recency : LRU(Least-Recently Used) : 최근에 사용되었다면 또 사용될 가능성이 있다
Frequency : LFU(Least-Frequently Used) : 자주 access된 경우 또 사용될 가능성이 있다
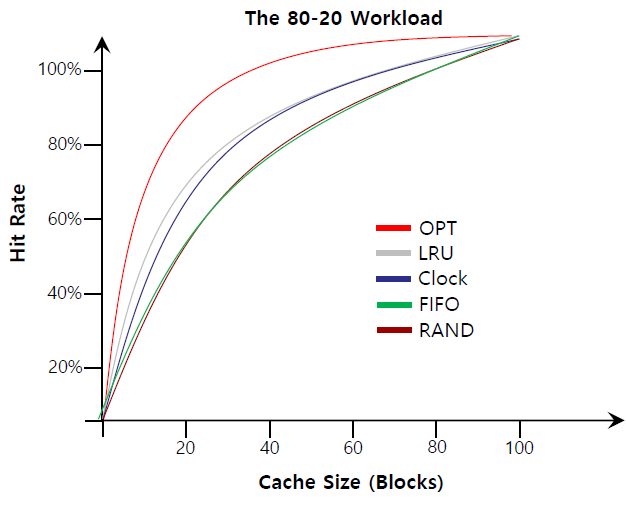
Workload Eample
| Locality가 없는 경우 | 80%확률로 Locality 발생 | 순서대로 반복적으로 page access |
 |
 |
 |
LRU Implementation with Counter
모든 page가 counter를 가지며 replace가 필요할 때 가장 작은 counter 확인
단점 : Table 탐색이 필요하다
LRU Implementation with Stack
linked-list 형태로 page number를 쌓음
단점 : update가 counter보다 비쌈 대신 Table 탐색은 불필요
Approximating LRU : Clock Algorithm
H/W에서 page가 referenced되면 reference bit을 1로 지정 -> never clear the bit -> OS에서 bit을 관리해야됨
Clock Algorithm
- 모든 page는 circular list로 배열됨
- 돌아가면서 reference bit확인하고 victim 선택
- if reference bit = 0 : victim으로 선택하고 evict
- if reference bit = 1 : 0으로 값 변경, victim 선택할때까지 다음 page 확인
Considering Dirty Page
H/W는 page가 수정되었는지에 대한 modified(or dirty) bit을 가진다
주로 replacement victim은 clean page가 선택된다
언제 Page를 Memory로 가져오나?
Demand Paging : Page Fault가 나면 그제서야 memory로 가져오는 것
Prefetching : Locality에 따라 access된 page의 인접한 page들도 memory로 가져오는 것
Eviction of Dirty pages : Clustering, Grouping
Locality에 따라 한번에 write한다 ( 여러번 작은 write보다 한번의 큰 write가 효율적이다 )
Thrashing : 모두 활발하게 작업되는데 physical memory가 한정되어있을 때 반복적으로 Page Fault 발생하는 것
- CPU 이용률이 최대에 달했을 때 multiprogramming정도가 더 커지는 경우 발생
학교 강의를 토대로 개인 공부 목적으로 작성되어 오타가 및 오류가 있을 수 있으며, 문제가 될 시 삭제될 수 있습니다.
'Study > 운영체제' 카테고리의 다른 글
| Chapter#19 I/O : HDD and RAID (0) | 2021.12.10 |
|---|---|
| Chapter#18 I/O Device (0) | 2021.12.10 |
| Chapter#16 Paging Advanced (0) | 2021.12.09 |
| Chapter#15 Paging (0) | 2021.12.09 |
| Chapter#14 Segmentation (0) | 2021.12.08 |



